



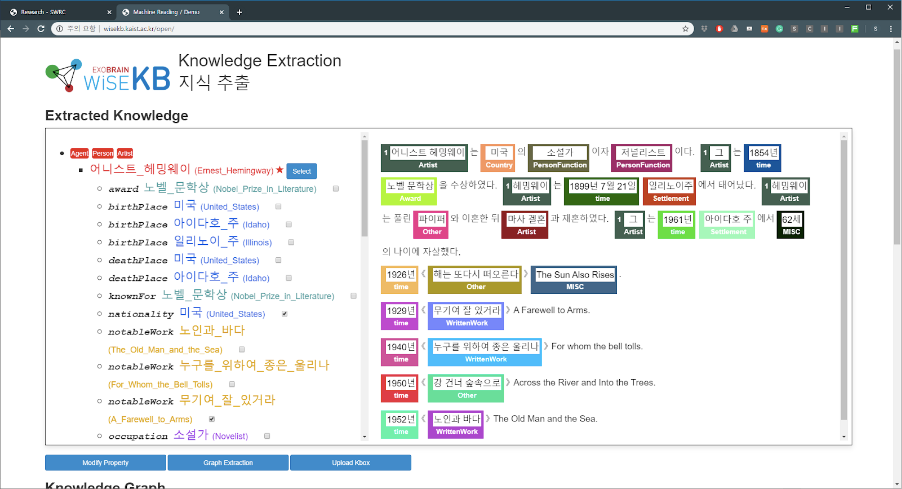
The recent victory of IBM Watson over human competitors in a quiz show provided a new impetus to almost all fields of artificial intelligence, such as natural language processing (NLP), question answering, knowledge representation, extraction, and reasoning. Research on knowledge extraction for enriching knowledge bases is currently underway to extract factual knowledge from unstructured text in the form of resource description framework (RDF) triples. Various large-scale knowledge bases such as Freebase, DBpedia, YAGO, and Wikidata are being widely used in many natural language processing (NLP) tasks. Creating a factual knowledge base using the knowledge extraction method means successfully answering the following two questions regarding the natural language text: (1) What are the entities doing? (2) How are the entities related to each other?
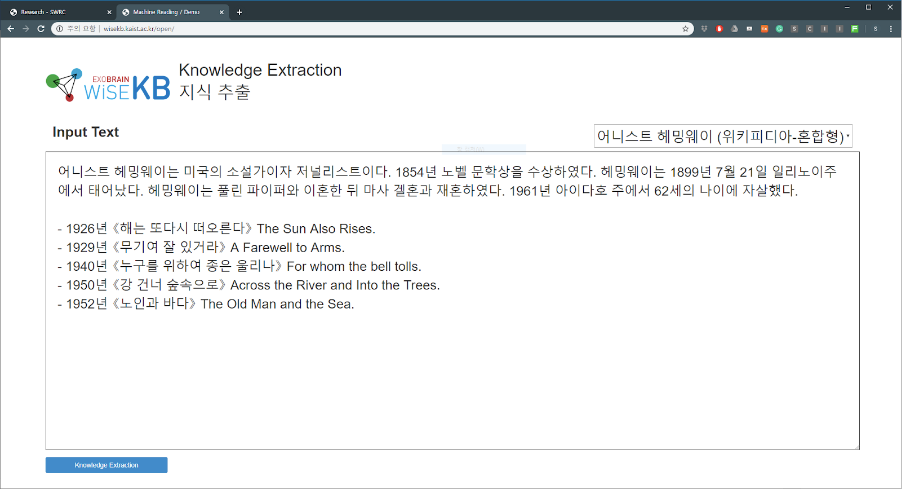
The SWRC of Prof. Key-Sun Choi from the School of Computing at KAIST presents KaiKES, a novel deep learning and crowdsourcing-based machine reading framework. Machine reading or knowledge extraction requires two steps; entity linking and relation extraction. In the entity linking step, entities that can be linked to a knowledge base are identified from natural language text. Next, in the relation extraction step, the relations between entities are classified and knowledge is extracted from natural language sentences in the form of structured data. Entity linking and relation extraction are indispensable subtasks for knowledge extraction. They are often accompanied by entity discovery, co-reference resolution, and knowledge validation to maximize the recall and precision of knowledge extraction.
With recent advances in deep learning technology, high-performance deep learning architectures such as convolutional neural networks, long short-term memory, and transformer have emerged and been used in all phases of knowledge extraction. A large amount of training data needs to be fed into these neural network architectures. Training data have been generated by experts, but this method is extremely cost-intensive and time-consuming. To overcome this drawback, using the single corpus, the SWRC team generates crowdsourcing data to execute the four tasks (entity mention detection, entity linking, co-reference resolution, and relation extraction) of knowledge extraction and presents the results of training with a state-of-the-art model based on the collected data.
These crowdsourcing data can test entity mention detection and linking, coreference resolution, and relation with the same document; then, a full performance test can be conducted from the knowledge extraction perspective. In addition, the effect of error generated in the previous step on subsequent steps can be tested. For example, in the researchers’ experience, errors in entity linking had an adverse effect on the learning relation extraction model. Therefore, when creating crowdsourcing data, they decided that using a common source text rather than different source texts for each task would be helpful for the overall analysis of information extraction.
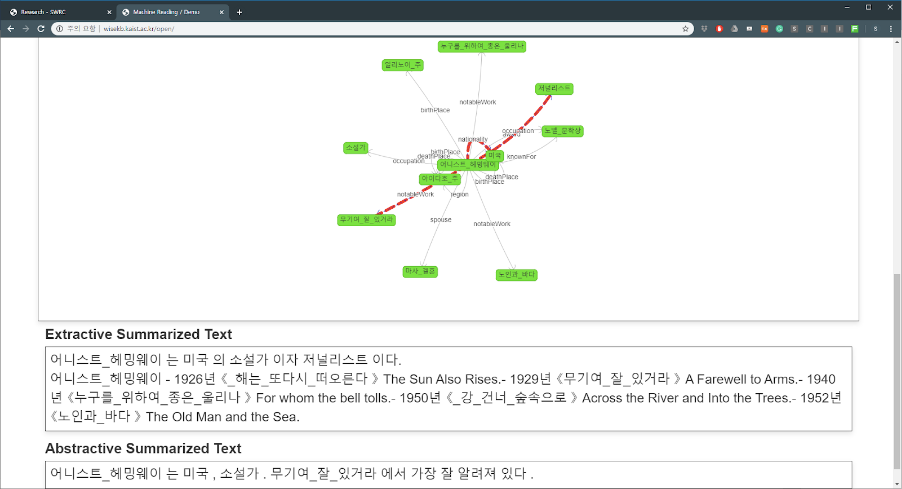
The experimental results served as initiative results for each Korean knowledge extraction task. This crowdsourcing data for Korean knowledge extraction are the first of their kind and will be a Korean knowledge extraction initiative point and promote research in this field. KaiKES aims to build linked open data by extracting knowledge from a text written in the Korean language and using crowdsourced data for each subtask to achieve high extraction performance. To create a knowledge extraction system which typically requires several subtasks to be performed, a framework is required to combine the modules. The goal of the framework is to define the I/O of each model and to improve the overall system performance by improving the performance of each model. The result of this research has been accepted for LREC 2020. Anyone interested in KaiKES can experience it at http://wisekb.kaist.ac.kr.
Prof. Key-Sun Choi School of Computing, KAIST
Homepage: http://semanticweb.kaist.ac.kr
E-mail: kschoi@kaist.ac.kr
