



Important academic progress toward achieving human-level intelligence of complex robotic systems has been made by the research team led by Prof. Han-Lim Choi (Dept. of Aerospace Engineering, KI for Robotic), who has developed a deep learning framework for efficient representation and control of high-dimensional dynamical systems.
Reinforcement learning is one promising solution framework to achieve human-level intelligence in many types of decision making and control tasks, as demonstrated in AlphaGo and AlphaStar. As such, there have been substantial achievements in applying reinforcement learning to control of high-dimensional dynamic systems such as humanoid and flapping robots. While some success stories are being reported, there remain significant challenges to tackle in order to achieve human-level intelligence with such a complex robot.
The core of intelligence is not just to learn a policy for a particular problem instance, but to solve various multiple tasks or immediately adapt to a new task. Given that huge computational burden makes it unrealistic to learn an individual policy for every conceivable task, a robot should be able to reason about its actions. This reasoning basically requires prediction about the consequences of actions, but such predictions are never trivial for a high-dimensional dynamic system, for several reasons: first, it is very difficult to obtain an exact internal dynamic model directly from the high-dimensional observation space; second, most available tools to choose the best sequence of actions are intractable for use in a high-dimensional system.
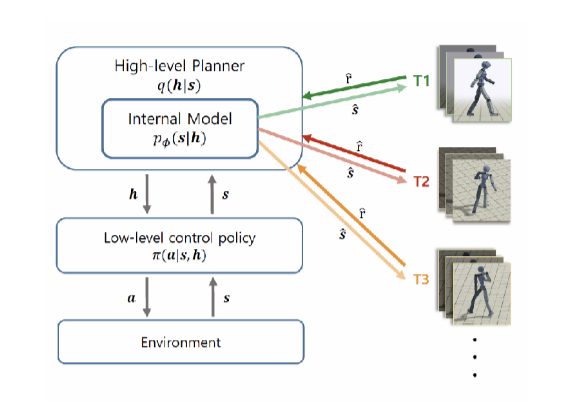
There is evidence in cognitive science is that there exists a certain type of hierarchical structure in the human motor control scheme that addresses the aforementioned fundamental difficulty. Such a hierarchical structure is known to utilize two levels of parallel control loops, operating at different time scales; at coarser scale, the high-level loop generates task-relevant commands for the agent to perform a given task; then, in a finer time scale, the low-level loop maps those commands to control signals while actively reacting to disturbances that the high-level loop was unable to consider. The high-level loop focuses only on the task-relevant aspects of the environment dynamics that can be represented in low-dimensional form. Consequently, this hierarchical structure allows for efficient prediction and planning of future states to compute commands.
Inspired by this process of hierarchical reasoning, Prof. Han-Lim Choi’s research group has proposed a learning framework, illustrated in Fig. 1, that extracts high-level intentions from a set of time-series motion data, as well as developing a low-level control policy to accomplish a desired sequence of high-level intentions. Two different types of learning are involved: (i) a low dimensional latent representation for an internal model should be obtained from agent’s own experiences via self-supervised learning; (ii) a control policy should be learned while interacting with the environment via reinforcement learning. The research team has combined these two learning problems by transforming a multitask reinforcement learning problem into a generative model, learning to use the control-inference duality. In this perspective, an agent equipped with a low-level control policy is viewed as a generative model that outputs trajectories according to high-level commands. Reasoning for the high-level commands is then considered as a posterior inference problem. As illustrated in Fig. 2, a virtual humanoid that learns its motion structure can produce control actions to reach the goal position while avoiding complicated obstacles.
The representation learning part of this research was presented at the Conference on Neural Information Systems (NeurIPS) 2018 and has been published in a Special Issue on Machine Learning in the Journal of Statistical Mechanics: Theory and Experiment (Impact Factor: 2.371) in Dec. 2019. The reinforcement learning part of this work was submitted to IEEE Robotics and Automation Letters in Feb. 2020, with a presentation option at the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2020.

Prof. Han-Lim Choi Dept. of Aerospace Engineering, KAIST
Homepage: http://lics.kaist.ac.kr
E-mail: hanlimc@kaist.ac.kr
